Hyukryul
Yang
(Also called Henry Yang)
Visual Intelligence Laboratory
Department of CSE
Hong Kong University of Science and Technology
hr.yang@connect.ust.hk
I'm pursuing my M.Phil studies under supervision of Prof. Qifeng Chen. My main research interests are applications of audio-visual approaches using deep learning. Also, I'm interested in applying reinforcement-learning to Computer Vision area.
Publication
Hiding Video in Audio via Reversible Generative Models
International Conference on Computer Vision (ICCV), 2019Hyukryul Yang*, Hao Ouyang*, Vladlen Koltun, Qifeng Chen
Paper(TBA)
Demo(TBA)
Code(TBA)
Abstract
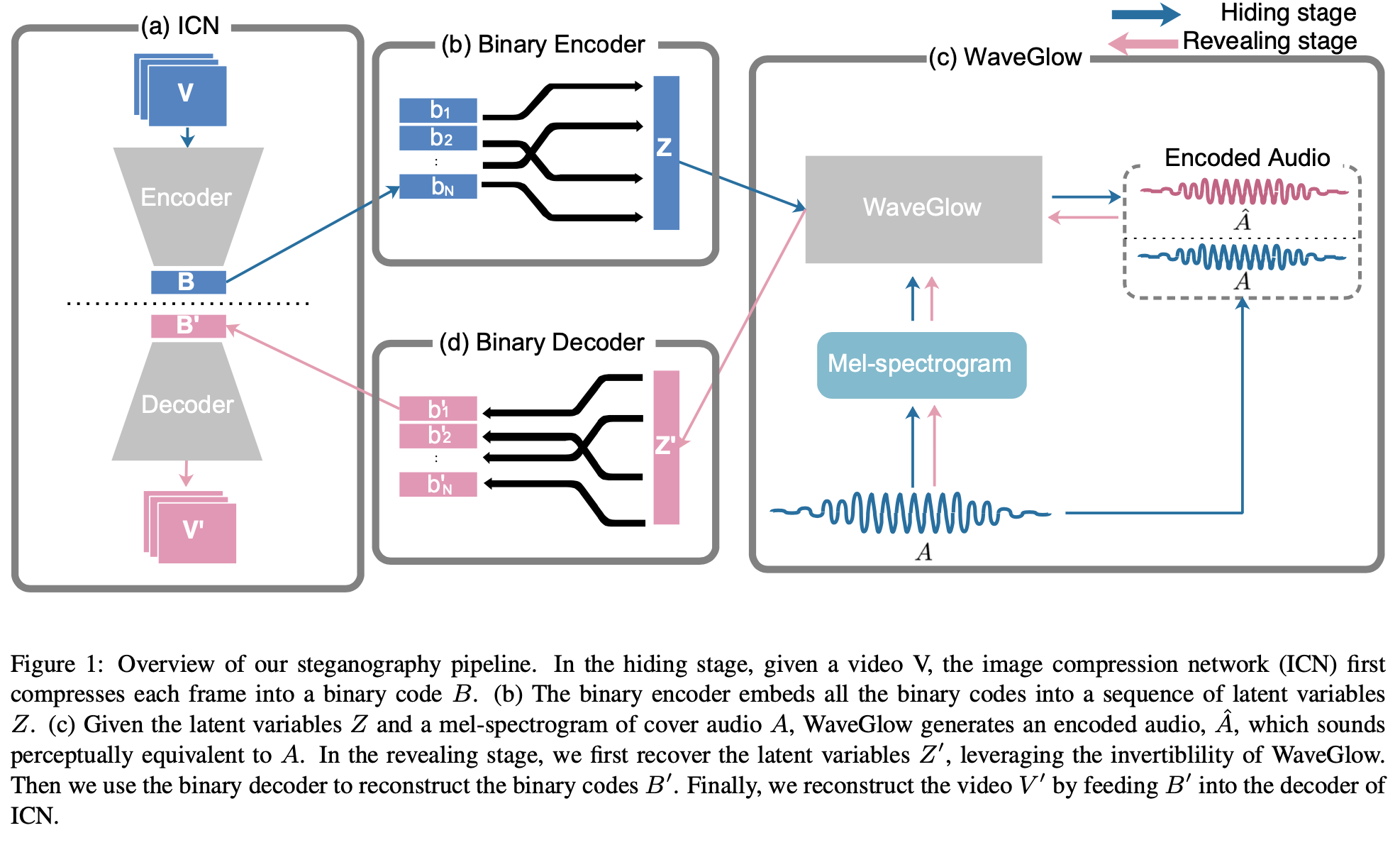
We present a method for hiding video content inside audio files while preserving the perceptual fidelity of the cover audio. This is a form of cross-modal steganography and is particularly challenging due to the high bitrate of video. Our scheme uses recent advances in flow-based generative models, which enable mapping audio to latent codes such that nearby codes correspond to perceptually similar signals. We show that compressed video data can be concealed in the latent codes of audio sequences while preserving the fidelity of both the hidden video and the cover audio. We can embed 128x128 video inside same-duration audio, or higher-resolution video inside longer audio sequences. Quantitative experiments show that our approach outperforms relevant baselines in steganographic capacity and fidelity.
Research Experience
Naver Clova AI
Researched how to predict CTR(Click-through rate) when advertisement images and user features are given.
Seoul National University
Researched how to generate matched human’s faces from human’s voices.
Activity
Co-author of “Introduction to Reinforcement Learning with Keras”
Published the first book on reinforcement learning in S.Korea.
Book InformationCode
PG(Policy Gradient) Travel
Implemented tutorial code of various policy gradient algorithms on Mujoco and Unity environment.
Code